Context free languages and Push-down automata
Question 1
Consider the following languages.
[caption width="800"]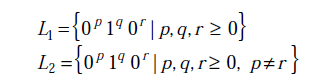 [/caption]
[/caption]
Which one of the following statements is FALSE?
Question 3
Let P be a regular language and Q be context-free language such that Q ⊆ P. (For example, let P be the language represented by the regular expression p*q* and Q be {pn qn | n ∈ N}). Then which of the following is ALWAYS regular?
(A) P ∩ Q
(B) P - Q
(C) ∑* - P
(D) ∑* - Q
Question 4
Consider the language L1,L2,L3 as given below.
L1={[Tex]0^{p}1^{q}[/Tex] | p,q [Tex]\\in[/Tex] N}
L2={[Tex]0^{p}1^{q}[/Tex] | p,q [Tex]\\in[/Tex] N and p=q}
L3={[Tex]0^{p}1^{q}0^{r}[/Tex] | p,q,r [Tex]\\in[/Tex] N and p=q=r}
Which of the following statements is NOT TRUE?
Question 5
Consider the languages -
L1 = {0i1j | i != j}.
L2 = {0i1j | i = j}.
L3 = {0i1j | i = 2j+1}.
L4 = {0i1j | i != 2j}.
Question 6
S -> aSa|bSb|a|b; The language generated by the above grammar over the alphabet {a,b} is the set of
Question 7
Let L = L1∩L2, where L1 and L2 are languages as defined below:
L1 = {am bm can bn | m, n >= 0}
L2 = {ai bj ck | i, j, k >= 0}
Then L is
Question 9
Consider the CFG with {S,A,B) as the non-terminal alphabet, {a,b) as the terminal alphabet, S as the start symbol and the following set of production rules
S --> aB S --> bA B --> b A --> a B --> bS A --> aS B --> aBB A --> bAAWhich of the following strings is generated by the grammar?
Question 10
For the correct answer strings to below grammar, how many derivation trees are there?
[caption width="800"] [/caption]
[/caption]There are 93 questions to complete.
Last Updated :
Take a part in the ongoing discussion