SQL
Question 1
Consider a database table T containing two columns X and Y each of type integer. After the creation of the table, one record (X=1, Y=1) is inserted in the table.
Let MX and My denote the respective maximum values of X and Y among all records in the table at any point in time. Using MX and MY, new records are inserted in the table 128 times with X and Y values being MX+1, 2*MY+1 respectively. It may be noted that each time after the insertion, values of MX and MY change. What will be the output of the following SQL query after the steps mentioned above are carried out?
SELECT Y FROM T WHERE X=7;
Question 2
A relational schema for a train reservation database is given below.
Passenger (pid, pname, age)
Reservation (pid, class, tid)
Table: Passenger pid pname age ----------------- 0 Sachin 65 1 Rahul 66 2 Sourav 67 3 Anil 69 Table : Reservation pid class tid --------------- 0 AC 8200 1 AC 8201 2 SC 8201 5 AC 8203 1 SC 8204 3 AC 8202What pids are returned by the following SQL query for the above instance of the tables?
SLECT pid
FROM Reservation ,
WHERE class ‘AC’ AND
EXISTS (SELECT *
FROM Passenger
WHERE age > 65 AND
Passenger. pid = Reservation.pid)
Question 3
Let R and S be relational schemes such that R={a,b,c} and S={c}. Now consider the following queries on the database:
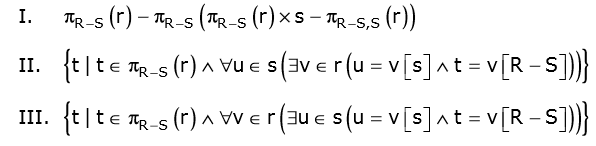

IV) SELECT R.a, R.b
FROM R,S
WHERE R.c=S.c
Which of the above queries are equivalent?
Question 4
Consider the table employee(empId, name, department, salary) and the two queries Q1 ,Q2 below. Assuming that department 5 has more than one employee, and we want to find the employees who get higher salary than anyone in the department 5, which one of the statements is TRUE for any arbitrary employee table?
Q1 : Select e.empId
From employee e
Where not exists
(Select * From employee s where s.department = “5” and
s.salary >=e.salary)
Q2 : Select e.empId
From employee e
Where e.salary > Any
(Select distinct salary From employee s Where s.department = “5”)
Question 5
Given the following schema:
employees(emp-id, first-name, last-name, hire-date, dept-id, salary)
departments(dept-id, dept-name, manager-id, location-id)
You want to display the last names and hire dates of all latest hires in their respective departments in the location ID 1700. You issue the following query:
SQL> SELECT last-name, hire-date
FROM employees
WHERE (dept-id, hire-date) IN ( SELECT dept-id, MAX(hire-date)
FROM employees JOIN departments USING(dept-id)
WHERE location-id = 1700
GROUP BY dept-id);
What is the outcome?
Question 6
SQL allows tuples in relations, and correspondingly defines the multiplicity of tuples in the result of joins. Which one of the following queries always gives the same answer as the nested query shown below:
select * from R where a in (select S.a from S)
Question 7
Consider the relation account (customer, balance) where customer is a primary key and there are no null values. We would like to rank customers according to decreasing balance. The customer with the largest balance gets rank 1. ties are not broke but ranks are skipped: if exactly two customers have the largest balance they each get rank 1 and rank 2 is not assigned
Query1: select A.customer, count(B.customer) from account A, account B where A.balance <=B.balance group by A.customer Query2: select A.customer, 1+count(B.customer) from account A, account B where A.balance < B.balance group by A.customerConsider these statements about Query1 and Query2.
1. Query1 will produce the same row set as Query2 for some but not all databases. 2. Both Query1 and Query2 are correct implementation of the specification 3. Query1 is a correct implementation of the specification but Query2 is not 4. Neither Query1 nor Query2 is a correct implementation of the specification 5. Assigning rank with a pure relational query takes less time than scanning in decreasing balance order assigning ranks using ODBC.Which two of the above statements are correct?
Question 8
The following table has two attributes A and C where A is the primary key and C is the foreign key referencing A with on-delete cascade.
A C ----- 2 4 3 4 4 3 5 2 7 2 9 5 6 4The set of all tuples that must be additionally deleted to preserve referential integrity when the tuple (2,4) is deleted is:
Question 9
The relation book (title, price) contains the titles and prices of different books. Assuming that no two books have the same price, what does the following SQL query list?
select title
from book as B
where (select count(*)
from book as T
where T.price > B.price) < 5
Question 10
Consider the following SQL query
select distinct al, a2,........., an from r1, r2,........, rm where PFor an arbitrary predicate P, this query is equivalent to which of the following relational algebra expressions ? A: [Tex]\\prod_{a_{1},a_{2},...a_{n}}\\sigma_{\\rho} (r_{1}\\times r_{2}\\times r_{3}....\\times r_{m})[/Tex] B: [Tex]\\prod_{a_{1},a_{2},...a_{n}}\\sigma_{\\rho} (r_{1}\\bowtie r_{2}\\bowtie r_{3}....\\bowtie r_{m})[/Tex] C: [Tex]\\prod_{a_{1},a_{2},...a_{n}}\\sigma_{\\rho} (r_{1}\\cup r_{2}\\cup r_{3}....\\cup r_{m})[/Tex] D: [Tex]\\prod_{a_{1},a_{2},...a_{n}}\\sigma_{\\rho} (r_{1}\\cap r_{2}\\cap r_{3}....\\cap r_{m})[/Tex]
There are 66 questions to complete.
Last Updated :
Take a part in the ongoing discussion