
A relation R is defined on ordered pairs of integers as follows: (x,y) R(u,v) if x < u and y > v. Then R is:
\n","encodingFormat":"text/plain","suggestedAnswer":[null,{"@type":"Answer","position":2,"text":"\nA Partial Order but not a Total Order
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},{"@type":"Answer","position":3,"text":"\nA Total Order
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},{"@type":"Answer","position":4,"text":"\nAn Equivalence Relation
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"}],"acceptedAnswer":{"@type":"Answer","position":1,"text":"\nNeither a Partial Order nor an Equivalence Relation
\n","comment":{"@type":"Comment","text":"The correct answer is \nNeither a Partial Order nor an Equivalence Relation
\n"},"answerExplanation":{"@type":"Comment","text":"\nAn equivalence relation on a set x is a subset of x*x, i.e., a collection R of ordered pairs of elements of x, satisfying certain properties. Write “x R y\" to mean (x,y) is an element of R, and we say \"x is related to y,\" then the properties are: 1. Reflexive: a R a for all a Є R, 2. Symmetric: a R b implies that b R a for all a,b Є R 3. Transitive: a R b and b R c imply a R c for all a,b,c Є R.
\n\nAn partial order relation on a set x is a subset of x*x, i.e., a collection R of ordered pairs of elements of x, satisfying certain properties. Write “x R y\" to mean (x,y) is an element of R, and we say \"x is related to y,\"
\n\nthen the properties are:
\n\n1. Reflexive: a R a for all a Є R,
\n\n2. Anti-Symmetric: a R b and b R a implies that for all a,b Є R
\n\n3. Transitive: a R b and b R c imply a R c for all a,b,c Є R. An total order relation a set x is a subset of x*x, i.e., a collection R of ordered pairs of elements of x, satisfying certain properties.
\n\nWrite “x R y\" to mean (x,y) is an element of R, and we say \"x is related to y,\"
\n\nthen the properties are:
\n\n1. Reflexive: a R a for all a Є R,
\n\n2. Anti-Symmetric: a R b implies that b R a for all a,b Є R
\n\n3. Transitive: a R b and b R c imply a R c for all a,b,c Є R.
\n\n4. Comparability : either a R b or b R a for all a,b Є R.
\n\nAs given in question, a relation R is defined on ordered pairs of integers as follows: (x,y) R(u,v) if x < u and y > v , reflexive property is not satisfied here, because there is > or < relationship between (x ,y) pair set and (u,v) pair set .
\n\nOther way , if there would have been x <= u and y>= v (or x=u and y=v) kind of relation among elements of sets then reflexive property could have been satisfied. Since reflexive property in not satisfied here , so given relation can not be equivalence, partial orderor total order relation.
\n\nSo, option (A) is correct.
\n"},"encodingFormat":"text/plain"}},{"@type":"Question","eduQuestionType":"Multiple choice","learningResourceType":"Practice problem","name":"Question on GATE-CS-2006","text":"\nFor which one of the following reasons does Internet Protocol (IP) use the timeto- live (TTL) field in the IP datagram header
\n","encodingFormat":"text/plain","suggestedAnswer":[{"@type":"Answer","position":1,"text":"\nEnsure packets reach destination within that time
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},{"@type":"Answer","position":2,"text":"\nDiscard packets that reach later than that time
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},null,{"@type":"Answer","position":4,"text":"\nLimit the time for which a packet gets queued in intermediate routers.
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"}],"acceptedAnswer":{"@type":"Answer","position":3,"text":"\nPrevent packets from looping indefinitely
\n","comment":{"@type":"Comment","text":"The correct answer is \nPrevent packets from looping indefinitely
\n"},"answerExplanation":{"@type":"Comment","text":"\nThe TTL field in an IP packet header is decremented by one each time the packet passes through a router. If the TTL field reaches zero, the router discards the packet and sends an ICMP \"Time Exceeded\" message back to the sender. This prevents packets from circulating endlessly in the network due to routing loops or other issues.
So, the reason IP uses the TTL field is to \"Prevent packets from looping indefinitely.\"
\r\nS -> S * E\r\nS -> E\r\nE -> F + E\r\nE -> F\r\nF -> id\r\nConsider the following LR(0) items corresponding to the grammar above.
\r\n(i) S -> S * .E\r\n(ii) E -> F. + E\r\n(iii) E -> F + .E\r\nGiven the items above, which two of them will appear in the same set in the canonical sets-of-items for the grammar? \n","encodingFormat":"text/plain","suggestedAnswer":[{"@type":"Answer","position":1,"text":" (i) and (ii) ","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},{"@type":"Answer","position":2,"text":"(ii) and (iii)","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},{"@type":"Answer","position":3,"text":"(i) and (iii) ","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},null],"acceptedAnswer":{"@type":"Answer","position":4,"text":"None of the above ","comment":{"@type":"Comment","text":"The correct answer is None of the above "},"answerExplanation":{"@type":"Comment","text":"Let\\'s make the LR(0) set of items. First we need to augment the grammar with the production rule S\\' -> .S , then we need to find closure of items in a set to complete a set. Below are the LR(0) sets of items.\r\r
\r\r\r"},"encodingFormat":"text/plain"}},{"@type":"Question","eduQuestionType":"Multiple choice","learningResourceType":"Practice problem","name":"Question on GATE-CS-2006","text":"\nYou are given a free running clock with a duty cycle of 50% and a digital waveform f which changes only at the negative edge of the clock. Which one of the following circuits (using clocked D flip-flops) will delay the phase of f by 180°?
\n[caption width=\"800\"] [/caption][caption width=\"800\"]
[/caption][caption width=\"800\"] [/caption]","encodingFormat":"text/plain","suggestedAnswer":[{"@type":"Answer","position":1,"text":"\n
[/caption]","encodingFormat":"text/plain","suggestedAnswer":[{"@type":"Answer","position":1,"text":"\nA
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},{"@type":"Answer","position":2,"text":"\nB
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},null,{"@type":"Answer","position":4,"text":"\nD
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"}],"acceptedAnswer":{"@type":"Answer","position":3,"text":"\nC
\n","comment":{"@type":"Comment","text":"The correct answer is \nC
\n"},"answerExplanation":{"@type":"Comment","text":"\nWe assume the D flip-flop to be negative edge triggered. In option (A), during the negative edge of the clock, first flip-flop inverts complement of ‘f’(we get f as the output). But, the complement of the output of first flip-flop(i.e. f\\') is given as the input to the second flip-flop. The second flip flop is enabled by \\'clk\\'. The output at the second flip flop is f\\'+90 degrees (as +ve edged clk at output delays it by 90 degrees). Thus f is delayed by 270 degrees. So, A is not the correct option. Following the above procedures as in (A) we will get:In option (B) and (D), the output is ‘f’. But, we want inverted ‘f’ as the output. So, (B) and (D) can’t be the answer. In option (C), the first flip-flop is activated by ‘clk’. So, the output of first flip-flop has the same phase as ‘f’. But, the second flip-flop is enabled by complement of ‘clk’. Since the clock ‘clk’ has a duty cycle of 50% , we get the output having phase delay of 180 degrees. Therefore, (C) is the correct answer.
\n"},"encodingFormat":"text/plain"}},{"@type":"Question","eduQuestionType":"Multiple choice","learningResourceType":"Practice problem","name":"Question on GATE-CS-2006","text":"\nA CPU has 24-bit instructions. A program starts at address 300 (in decimal). Which one of the following is a legal program counter (all values in decimal)?
\n","encodingFormat":"text/plain","suggestedAnswer":[{"@type":"Answer","position":1,"text":"\n400
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},{"@type":"Answer","position":2,"text":"\n500
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"},null,{"@type":"Answer","position":4,"text":"\n700
\n","comment":{"@type":"Comment","text":"This is not the correct answer"},"encodingFormat":"text/plain"}],"acceptedAnswer":{"@type":"Answer","position":3,"text":"\n600
\n","comment":{"@type":"Comment","text":"The correct answer is \n600
\n"},"answerExplanation":{"@type":"Comment","text":"\nEach address is multiple of 3 as the starting address is 300 and is each instruction consists of 24 bit, i.e., 3 byte.
Thus, in the given options the valid counter will be the one which is the multiple of 3. Out of the options we can see that only 600 satisfies the condition.
Therefore, it is 600.
Question 1
Question 2
Question 3
Question 4
A relation R is defined on ordered pairs of integers as follows: (x,y) R(u,v) if x < u and y > v. Then R is:
Question 5
For which one of the following reasons does Internet Protocol (IP) use the timeto- live (TTL) field in the IP datagram header
Question 6
Question 7
S -> S * E S -> E E -> F + E E -> F F -> idConsider the following LR(0) items corresponding to the grammar above.
(i) S -> S * .E (ii) E -> F. + E (iii) E -> F + .EGiven the items above, which two of them will appear in the same set in the canonical sets-of-items for the grammar?
Question 8
You are given a free running clock with a duty cycle of 50% and a digital waveform f which changes only at the negative edge of the clock. Which one of the following circuits (using clocked D flip-flops) will delay the phase of f by 180°?
[caption width="800"]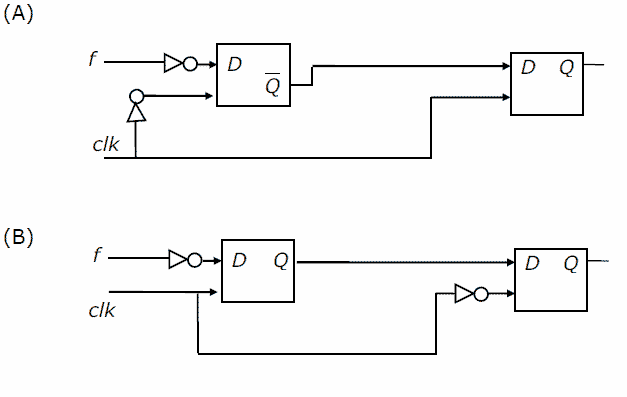 [/caption][caption width="800"]
[/caption][caption width="800"]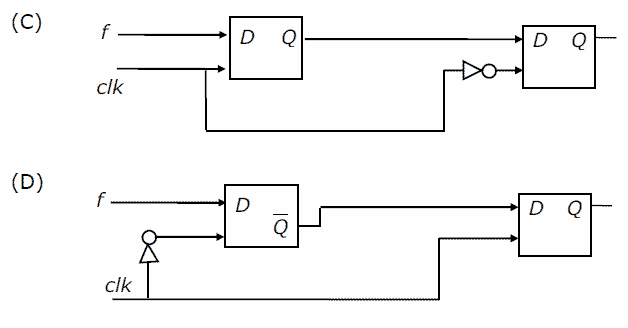 [/caption]
[/caption]Question 9
A CPU has 24-bit instructions. A program starts at address 300 (in decimal). Which one of the following is a legal program counter (all values in decimal)?
Question 10
There are 84 questions to complete.