GATE-CS-2014-(Set-1)
Question 1
Which of the following options is the closest in meaning to the phrase underlined in the sentence
below?
It is fascinating to see life forms cope with varied environmental conditions.
Question 2
In a press meet on the recent scam, the minister said, "The buck stops here". What did the minister convey by the statement?
Question 4
The roots of ax2 + bx + c are real and positive. a, b and c are real. Then ax2 + b|x| + c
has
Question 5
The Palghat Gap (or Palakkad Gap), a region about 30 km wide in the southern part of the Western Ghats in India, is lower than the hilly terrain to its north and south. The exact reasons for the formation of this gap are not clear. It results in the neighbouring regions of Tamil Nadu getting more rainfall from the South West monsoon and the neighbouring regions of Kerala having higher summer temperatures. What can be inferred from this passage?
Question 6
Geneticists say that they are very close to confirming the genetic roots of psychiatric illnesses such as depression and schizophrenia, and consequently, that doctors will be able to eradicate these diseases through early identification and gene therapy.
On which of the following assumptions does the statement above rely?
Question 7
Round-trip tickets to a tourist destination are eligible for a discount of 10% on the total fare. In addition, groups of 4 or more get a discount of 5% on the total fare. If the one way single person fare is Rs 100, a group of 5 tourists purchasing round-trip tickets will be charged Rs _________.
Question 8
In a survey, 300 respondents were asked whether they own a vehicle or not. If yes, they were further asked to mention whether they own a car or scooter or both. The responses are tabulated below.
[caption width="800"]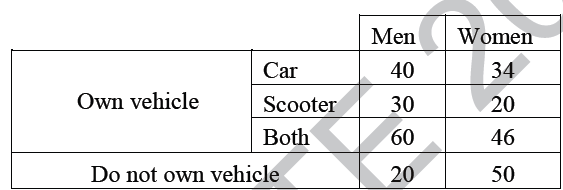 [/caption]
[/caption]
What percent of respondents do not own a scooter?
Question 9
When a point inside of a tetrahedron (a solid with four triangular surfaces) is connected by straight lines to its corners, how many (new) internal planes are created with these lines? _____________
Question 10
Consider the statement
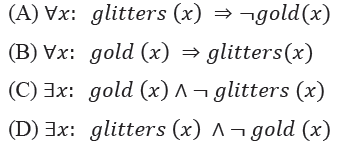
“Not all that glitters is gold”Predicate glitters(x) is true if x glitters and predicate gold(x) is true if x is gold. Which one of the following logical formulae represents the above statement?
There are 65 questions to complete.
Last Updated :
Take a part in the ongoing discussion