GATE-CS-2014-(Set-3)
Question 1
If she _______________ how to calibrate the instrument, she _______________ done the experiment.
Question 4
The table below has question-wise data on the performance of students in an examination. The marks for each question are also listed. There is no negative or partial marking in the examination.
 What is the average of the marks obtained by the class in the examination
What is the average of the marks obtained by the class in the examination
What is the average of the marks obtained by the class in the examinationQuestion 5
A dance programme is scheduled for 10.00 a.m. Some students are participating in the programme and they need to come an hour earlier than the start of the event. These students should be accompanied by a parent. Other students and parents should come in time for the programme. The instruction you think that is appropriate for this is
Question 6
By the beginning of the 20th century, several hypotheses were being proposed, suggesting a paradigm shift in our understanding of the universe. However, the clinching evidence was provided by experimental measurements of the position of a star which was directly behind our sun. Which of the following inference(s) may be drawn from the above passage?
(i) Our understanding of the universe changes
based on the positions of stars
(ii) Paradigm shifts usually occur at the
beginning of centuries
(iii) Stars are important objects in the
universe
(iv) Experimental evidence was important in
confirming this paradigm shift
Question 7
The Gross Domestic Product (GDP) in Rupees grew at 7% during 2012-2013. For international comparison, the GDP is compared in US Dollars (USD) after conversion based on the market exchange rate. During the period 2012-2013 the exchange rate for the USD increased from Rs. 50/ USD to Rs. 60/ USD. India’s GDP in USD during the period 2012-2013
Question 8
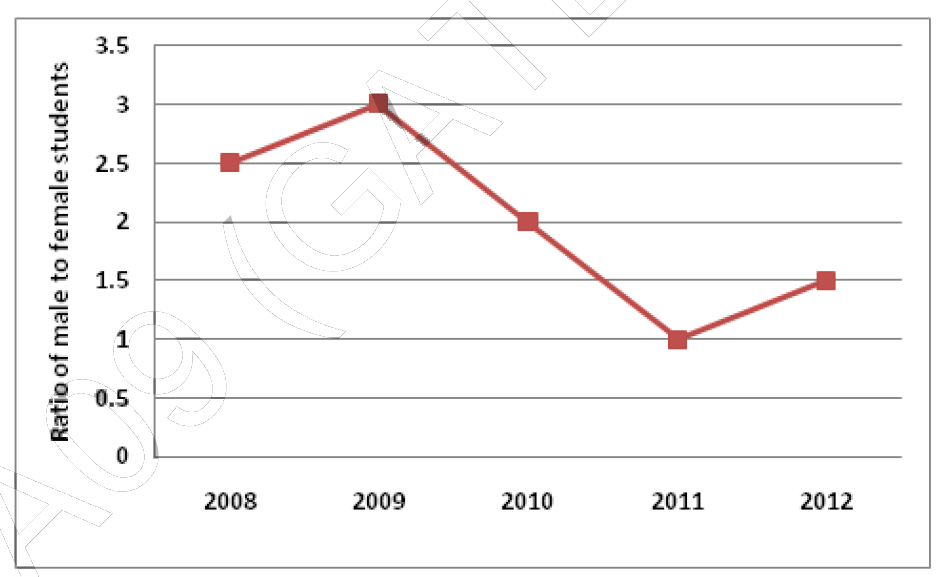
The ratio of male to female students in a college for five years is plotted in the following line graph. If the number of female students in 2011 and 2012 is equal, what is the ratio of male students in 2012 to male students in 2011?
Question 9
Consider the equation: (7526)8 − (Y)8 = (4364)8 , where (X)N stands for X to the base N. Find Y.
Question 10
Consider the following statements:
P: Good mobile phones are not cheap Q: Cheap mobile phones are not good L: P implies Q M: Q implies P N: P is equivalent to QWhich one of the following about L, M, and N is CORRECT?
There are 65 questions to complete.
Last Updated :
Take a part in the ongoing discussion