- Courses
- Tutorials
- Jobs
- Practice
- Contests
Gate IT 2005
Question 1
A bag contains 10 blue marbles, 20 green marbles and 30 red marbles. A marble is drawn from the bag, its colour recorded and it is put back in the bag. This process is repeated 3 times. The probability that no two of the marbles drawn have the same colour is
Question 2
If the trapezoidal method is used to evaluate the integral obtained 0∫1x2dx ,then the value obtained

Question 4
Let L be a regular language and M be a context-free language, both over the alphabet Σ. Let Lc and Mc denote the complements of L and M respectively. Which of the following statements about the language Lc∪ Mc is TRUE
Question 8
Using Booth\'s Algorithm for multiplication, the multiplier -57 will be recoded as
Question 9
A dynamic RAM has a memory cycle time of 64 nsec. It has to be refreshed 100 times per msec and each refresh takes 100 nsec. What percentage of the memory cycle time is used for refreshing?
Question 10
A two-way switch has three terminals a, b and c. In ON position (logic value 1), a is connected to b, and in OFF position, a is connected to c. Two of these two-way switches S1 and S2 are connected to a bulb as shown below.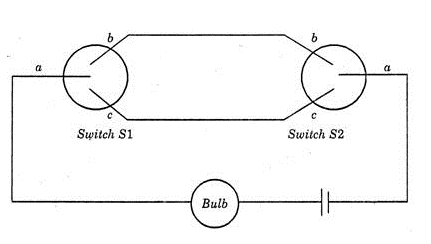 Which of the following expressions, if true, will always result in the lighting of the bulb ?
Which of the following expressions, if true, will always result in the lighting of the bulb ?
 Which of the following expressions, if true, will always result in the lighting of the bulb ?
Which of the following expressions, if true, will always result in the lighting of the bulb ?There are 90 questions to complete.
Last Updated :
Take a part in the ongoing discussion