GATE IT 2006
Question 1
In a certain town, the probability that it will rain in the afternoon is known to be 0.6. Moreover, meteorological data indicates that if the temperature at noon is less than or equal to 25°C, the probability that it will rain in the afternoon is 0.4. The temperature at noon is equally likely to be above 25°C, or at/below 25°C. What is the probability that it will rain in the afternoon on a day when the temperature at noon is above 25°C?
Question 2
For the set N of natural numbers and a binary operation f : N x N → N, an element z ∊ N is called an identity for f, if f (a, z) = a = f(z, a), for all a ∊ N. Which of the following binary operations have an identity?
- f (x, y) = x + y - 3
- f (x, y) = max(x, y)
- f (x, y) = xy
Question 3
In the automaton below, s is the start state and t is the only final state.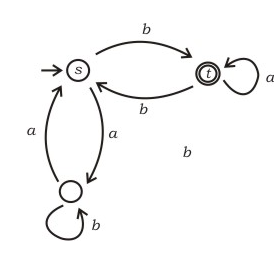 Consider the strings u = abbaba, v = bab, and w = aabb. Which of the following statements is true?
Consider the strings u = abbaba, v = bab, and w = aabb. Which of the following statements is true?
 Consider the strings u = abbaba, v = bab, and w = aabb. Which of the following statements is true?
Consider the strings u = abbaba, v = bab, and w = aabb. Which of the following statements is true?
Question 4
In the context-free grammar below, S is the start symbol, a and b are terminals, and ϵ denotes the empty string
S → aSa | bSb | a | b | ϵ
Which of the following strings is NOT generated by the grammar?
Question 5
Which regular expression best describes the language accepted by the non-deterministic automaton below?
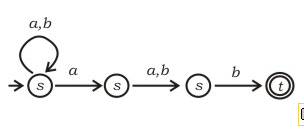

Question 6
The addition of 4-bit, two\'s complement, binary numbers 1101 and 0100 results in
Question 7
Which of the following DMA transfer modes and interrupt handling mechanisms will enable the highest I/O band-width?
Question 8
In a binary tree, the number of internal nodes of degree 1 is 5, and the number of internal nodes of degree 2 is 10. The number of leaf nodes in the binary tree is
Question 9
Given a boolean function f (x1, x2, ..., xn), which of the following equations is NOT true
Question 10
If all the edge weights of an undirected graph are positive, then any subset of edges that connects all the vertices and has minimum total weight is a
There are 86 questions to complete.
Last Updated :
Take a part in the ongoing discussion